Реалізація вимог швидкого початкового завантаження за допомогою ОСРВ QNX Neutrino
Введение
После загрузки системы во многих встраиваемых приложениях должны быть выполнены определенные действия в течение жестко ограниченного временного отрезка. Удовлетворение таким жестким временным условиям может оказаться непростой задачей, и при проектировании системный архитектор должен вести разработку, всегда имея в виду требования этого начального этапа загрузки. С точки зрения работы программного обеспечения процесс начальной загрузки включает несколько этапов. Во-первых, должна произойти загрузка операционной системы реального времени (ОСРВ) из энергонезависимой памяти, флэш-памяти или с жесткого диска. Затем должна пройти самоинициализация ОСРВ, а также должны быть загружены драйверы внутренних и периферийных устройств. После этого загружаются, инициализируются и начинают работу прикладные программы. Все эти этапы требуют определенного времени, и системный архитектор или разработчик должны продумать до конца особенности каждого этапа, чтобы гарантировать инициализацию и готовность всех компонентов оборудования и программного обеспечения так, как это необходимо.
Требования, предъявляемые к этапу начальной загрузки, имеют особое значение для применения в автомобильных системах. Обычно автомобильная система должна начать получение сообщений по шине и реагировать на них в течение 50 мс после включения питания. Радиосистемы тоже имеют свои требования по "раннему появлению звука", в которые входит интервал времени от момента "зажигание включено" (что соответствует началу загрузки системы) до момента, когда пассажиры начинают слышать радио. Это время может изменяться, но обычно оно составляет 1-4 с после загрузки системы. В более изощренных радиосистемах может выдвигаться несколько требований по первоначальному появлению звука. Например, звучание FM-радио должно появляться через 1 с, спутниковое радио должно зазвучать через 3 с, а проигрывание MP3-мелодий с USB-карты памяти начнется через 4 с. Системы с экранами имеют свои требования по раннему появлению видеоизображения для поддержки камер заднего вида, навигационных приложений или экранов-заставок.
В настоящей статье рассматриваются ситуации с удовлетворением требований для достаточно большого времени загрузки, от одной секунды и более. Такие события обычно обрабатываются на уровне кода приложения, поэтому эти приложения должны запускаться сразу после загрузки ОСРВ. Следовательно, основное внимание нужно обращать на оптимизацию этапов начальной загрузки ОСРВ и приложений, делая эти этапы как можно более эффективными и быстрыми. Данная статья может служить для системного архитектора своего рода трамплином, поскольку в ней описывается некоторое число технологий и стратегий. Эти технологии опираются на работу с ОСРВ QNX® Neutrino®, хотя некоторые приемы могут быть также применены и к другим операционным системам.
Обычно полнофункциональная ОСРВ не может достаточно быстро выполнять процесс загрузки и инициализации, чтобы удовлетворять условиям раннего реагирования при загрузке со временем, меньшим чем 100 мс. Для получения времен такого порядка разработчикам системы нужно решение такого типа как тот, что предоставляется Технологическим пакетом разработчика (TDK) для мгновенной активации устройств в QNX (QNX Instant Device Activation Technology Development Kit). В статье не рассматриваются особенности этой технологии, разве что в той части, которая касается интересующих нас времен большего порядка.
Последовательность начального запуска
Как и большинство операционных систем, ОСРВ QNX Neutrino имеет несколько этапов загрузки (см. рис. 1).
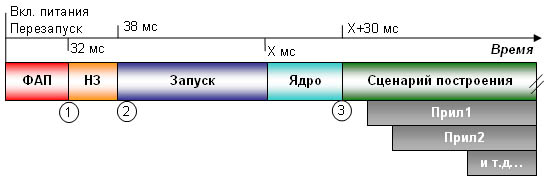
Рис. 1. Процесс начальной загрузки QNX Neutrino (длительности даны не в масштабе).
Ниже следует краткое описание каждого этапа.
-
ФАП (фазовая автоподстройка, phased locked loop, PLL). В данной статье под ФАП понимается процесс, длящийся от подачи питания на процессор до начала выполнения процессором первой инструкции. Для большинства ЦПУ процесс ФАП занимает время, за которое исходная тактовая частота задающего генератора проходит через все таймеры, используемые кристаллом. Время, занимаемое процессом ФАП для получения необходимых частот, обычно соответствует наибольшей временной метке, требуемой для запуска процессора. Время этапа ФАП не зависит от загружаемой ОС и меняется в зависимости от типа ЦПУ. В некоторых случаях это время может быть более 32 мс. Для получения точных значений обратитесь к руководству по ЦПУ.
-
НЗ (начальный загрузчик, initial program loader, IPL). В QNX используется стандартный начальный загрузчик, который выполняет минимально необходимые операции для подготовки памяти, инициализации выбора нужных микросхем и конфигурирования других, необходимых для работы ЦПУ установок. После окончания этих установок начальный загрузчик копирует в ОЗУ программу Запуска и передает ей управление.
Стандартный начальный загрузчик QNX может быть заменен любым другим. Среди таких замен могут быть полнофункциональные продукты типа U-Boot или RedBoot, которые через канал TFTP-клиента передают новый образ загрузки и записывают его во флеш-память. Обычно работа начального загрузчика продолжается не менее 6 мс до того, как начнется загрузка в память образа ОС. Фактическое время зависит от архитектуры ЦПУ, от того, что требуется материнской плате для определения минимальной конфигурации и что выбранный начальный загрузчик делает перед началом передачи управления ОС.
-
Запуск (Startup). На этапе запуска происходит копирование образа ОС из флеш-памяти в ОЗУ и запуск образа на выполнение. Эта фаза копирования составляет самую длительную часть процесса начальной загрузки ОСРВ QNX Neutrino. То есть, системному архитектору есть над чем поработать, чтобы обеспечить управление длительностью этой фазы, пусть даже косвенное.
В ОСРВ QNX Neutrino файловая система на базе образа ОС (IFS, image file system) содержит как собственно образ ОС, так и программу Запуска (которые начальный загрузчик копирует в ОЗУ). Образ ОС состоит из ядра, сценария построения и любых других драйверов, приложений и бинарных кодов, которые необходимы системе. Поскольку вы можете управлять составом IFS, то и время выполнения данного этапа есть величина переменная. На рис. 1 она обозначена значением Х. Это время может составлять и 200 мс, и 2-3 с. В некоторых особых случаях, когда система имеет образ большого размера и не имеет никакой другой файловой системы, кроме IFS, этап Запуска может продолжаться дольше (до 10 и более секунд).
Для добавления, удаления или конфигурирования файлов, хранящихся в IFS можно отредактировать сценарий построения или использовать инструмент построителя встраиваемых конфигураций в интегрированной среде разработки QNX Momentics® IDE.
-
Ядро (Kernel). На этапе запуска ядра инициализируется блок управления памятью (MMU, memory management unit), создаются структуры для управления страницами, процессами и исключениями, а также разрешается работа системы прерываний. После завершения этого этапа ядро становится полностью работоспособным и может начать загрузку и запуск процессов пользователя из сценария построения.
-
Сценарий построения (build script). В сценарии определяется, какие драйверы и приложения должны быть запущены и в какой последовательности. Поскольку ОСРВ QNX Neutrino является микроядерной ОС, то каждый драйвер, сервер или приложение (Прил1, Прил2 и т.д. на рис. 1) запускаются в виде отдельного загружаемого процесса пользовательского уровня. Такой подход имеет явные преимущества: вам не нужно ждать загрузки и инициализации ядра и полного набора драйверов, прежде чем приложениям будет передано управление. При запущенном микроядре можно чередовать запуск драйверов и приложений, чтобы достичь максимально быстрого завершения этапа запуска системы. Дальше на этом мы остановимся подробнее.
Измерение времени начальной загрузки
Для оптимизации любого этапа начальной загрузки необходимо измерить его длительность, изменить код и опять провести измерения, чтобы оценить, насколько изменилось время в лучшую сторону. Для измерения времени существует некоторая базовая техника, и ее применимость зависит от начальной точки измерения. Если вы посмотрите на рис. 1, то можете заметить три ключевые точки, представленными числами в кружках:
-
Время, измеряемое до наступления события 1, то есть, до того момента, как ЦПУ начинает выполнение инструкций и когда требуется аппаратная поддержка.
-
Программное обеспечение может начать работу между точками 1 и 3, но не всегда используются одни и те же функции API. Например, код этапа Запуска не может использовать большинство служб ОСРВ, включая таймеры POSIX. В этой ситуации поддерживается лишь ограниченное подмножество функций – например, memcpy(), strcpy(), printf(), и kprintf(), — необходимых для выполнения элементарных операций.
-
При оптимизации времени после точки 3 вы получаете доступ ко всем функциям ОС, можете запускать любые программы и подключаться к интегрированной среде разработки QNX Momentics IDE с использованием всего ассортимента инструментальных средств.
|
Этап измерения |
Что используется |
Точность |
Описание |
За/Против |
|
После точки 3 |
TraceEvent() |
мс |
Используется отладочная версия микроядра (procnto-instr), сбор данных происходит с помощью tracelogger или системного профайлера QNX Momentics. В код клиента вставляются вызовы функции API TraceEvent(). |
При работе вашего процесса возможно отображение данных в графическом виде так же, как и всех других действий в системе. Разработчик должен установить отладочную версию микроядра. |
|
После точки 3 |
time |
мс |
Утилита командной строки выдает примерное время выполнения процесса. |
Результаты измерения недоступны до тех пор, пока интересующий процесс не завершится. |
|
После точки 3 |
ClockCycles() |
нс |
Эта системная функция API использует быстродействующий счетчик ЦПУ для подсчета числа тактов с момента подачи питания до точки, где происходит вызов функции ClockCycles(). |
Измеряется абсолютное время. Не обязательно соответствует времени, занимаемому измеряемым процессом, поскольку в микроядре за время измерения могут запускаться и другие потоки. |
|
После точки 3 |
slogf() / sloginfo |
c |
Функция API системного регистратора, используется вместе с slogger. |
Время измеряется неточно; используется, главным образом, для определения последовательности событий. |
|
Между точками 2 и 3 |
ClockCycles() (макрос) |
c |
Это не функция API, а макрос, в котором непосредственно считывается аппаратный счетчик ЦПУ. Выдаются те же результаты, что и для функции API уровня ОС с тем же именем, макрос доступен после загрузки микроядра. |
Поддерживается не во всех архитектурах; работает лишь в случае, если функция ClockCycles() производит считывание непосредственно из аппаратного регистра, а не вычисляется. |
|
Между точками 1 и 3 |
Интерфейс GPIO и осциллограф |
нс |
В коде клиента в различных местах подключаются и отключаются контакты общего интерфейса ввода/вывода (GPIO). По изменению уровней на этих контактах (появление импульсов) с помощью цифрового осциллографа измеряется интервал времени между событиями. |
Невозможно распознавание различных точек. Требуется наличие в системном оборудовании интерфейса GPIO, цифрового осциллографа и значительного времени на начальную подготовку. |
|
До точки 1 |
Аппаратные точки и осциллограф |
нс |
Измерения производятся на осциллографе в контактных точках оборудования (например, линия аппаратного сброса ЦПУ) и в точках интерфейса GPIO. |
То же, что и выше |
Таблица 1. Способы измерения времени начальной загрузки.
Для метода, использующего вызовы функции TraceEvent() необходимо использовать отладочную версию микроядра и в сценарии для раннего этапа начальной загрузки включить вызов tracelogger. Например, для протоколирования первых 10 секунд этапа загрузки нужно использовать такую команду:
tracelogger –n0 -s10
Подробности о том, как анализировать файл resulting.kev (трассировка событий микроядра) приведены в документации по QNX, описание команды tracelogger.
Для получения результатов измерения абсолютного времени после момента аппаратного сброса для различных точек сценария загрузки нужно просто вывести значения, выдаваемые функцией ClockCycles(); пример приведен в Листинге 1. Такой способ дает возможность измерить длительность выполнения кода для этапов НЗ и Запуск. Обычно данные от функции ClockCycles() используются для измерения относительных времен: вы записываете значения ClockCycles() для двух точек, а затем вычитаете первое значение из второго для получения длительности события. Функция ClockCycles() выдает значения абсолютного времени, прошедшего с подачи питания на ЦПУ.
Для такого метода нужно дать некоторые разъяснения:
-
Скоростной счетчик работает очень быстро, и он может переполниться. Поэтому такой метод лучше всего использовать для первых секунд работы ЦПУ.
-
В зависимости от того, как реализован сброс в пакете BSP (поддержка процессорных плат), программная команда закрытия (сброса) целевой системы (shutdown) может не выполнить очистку значения счетчика для функции ClockCycles(). В таком случае может потребоваться выключить и включить питание на устройстве.
-
Данный способ применим лишь к системам, где имеется скоростной аппаратный счетчик. В системах, где в ЦПУ нет такого счетчика, а происходит эмуляция циклов ЦПУ для работы функции ClockCycles(), вы не получите значений абсолютного времени, прошедшего с момента сброса.
#include
#include
#include
#include
#include
int main( int argc, char *argv[])
{
uint64_t timesinceboot_ms;
timesinceboot_ms = (ClockCycles() /
(SYSPAGE_ENTRY(qtime->cycles_per_sec/1000));
printf( "ClockCycles()=%llu ms
", timesinceboot_ms);
return EXIT_SUCCESS;
}
Листинг 1. Использование функции ClockCycles() для измерения времени, прошедшего с момента начального сброса.
Оптимизация начального загрузчика
Когда разработчики впервые начинают работать над программой начальной загрузки, разработка собственно загрузчика часто отходит на второй план. Далее приводится несколько рекомендаций по действиям, которые обычно упускаются из вида:
-
Как можно раньше разрешите программе и данным использовать кеш-память. Этот совет кажется очевидным, но большинство циклов копирования сжатых данных в начальном загрузчике выполняются существенно быстрее, если разрешена работа с кешем команд.
-
Минимизируйте или исключайте использование таймаутов в сценарии загрузки. Обычно загрузчики типа RedBoot и U-Boot, где запускается сценарий, содержат автоматический таймаут, во время которого можно остановить загрузку данной ОС и начать загрузку новой ОС. Использование таймаута удобно на этапе разработки, но в готовом продукте эти фрагменты нужно удалить. Кроме того, в начальном загрузчике на выход последовательного порта могут выводиться различные сообщения (например, справочная информация или просто приветствия); их тоже надо убрать. Для изменения существующих задержек в загрузчике U-Boot используйте переменные окружения bootdelay, bootcmd и preboot. Для загрузчика RedBoot для изменения значения Boot script timeout используйте команду fconfig.
-
Не выполняйте сканирование точки входа для образа ОС. Если в системе используется этап НЗ для QNX по умолчанию, то вам нужна только точка входа процедуры main() внутри файла main.c; удалите все ненужное. Особенно обратите внимание на код, где вызывается процедура image_scan(), и замените это место на вызов по фиксированному адресу нахождения образа ОС. Подсказка: если вы "ужимаете" программу ФАП до фиксированного размера, то вы всегда знаете, где находится точка входа в образ ОС.
-
Исключите процедуру вычисления контрольной суммы при загрузке. В большинстве случаев в системе имеется единственный образ ОС. Следовательно, вычисление контрольной суммы для подтверждения целостности образа имеет мало смысла, потому что вы не сможете выполнить восстановление образа, если с ним что-то произошло. А вычисление контрольной суммы занимает время. Удалив этот фрагмент, вы дадите возможность быстрее загрузиться нужному коду.
Копирование из флеш-памяти в ОЗУ
На этапах НЗ и Загрузка код копируется из флеш-памяти в ОЗУ, после чего запускается на выполнение. Время этой операции зависит от скорости работы ЦПУ и быстродействия чипа флеш-памяти. Для измерения этого времени копирования можно использовать код Листинга 2.
#include
#include
#include
#include
#include
#include
#include
#define MEGABYTE (1024*1024)
#define BLOCK_SIZE 16384
#define LOOP_RUNS 10
char *ram_destination;
char *ram_block;
char *flash_block;
unsigned long flash_addr;
uint64_t cycles_per_sec;
double CopyTest(const char *msg, char *source, char *dest)
{
uint64_t accum = 0, start, stop;
double t;
int i;
for (i=0; i<LOOP_RUNS; i++)
{
start = ClockCycles();
memcpy(dest, source, BLOCK_SIZE);
stop = ClockCycles();
accum += (stop - start);
}
accum /= LOOP_RUNS;
t = accum*(MEGABYTE/BLOCK_SIZE); // t = cycles per MB
t = t / cycles_per_sec; // t = seconds per 1MB
printf("
To copy %s to RAM takes:
",msg);
printf(" %llu clock cycles for %u bytes
", accum, BLOCK_SIZE);
printf(" %f milliseconds per 1MB bytes
", t*1000);
printf(" %f microseconds per 1KB bytes
", t*1000);
return t;
}
int main(int argc, char *argv[])
{
double flashtime, ramtime;
if (argc<1) {
printf("%s requires address of flash (any 16K block will do)
", argv[0]);
return EXIT_FAILURE;
}
flash_addr = strtoul(argv[1], 0, 16);
printf("Using flash physical address at %lx
", flash_addr);
ram_block = malloc(BLOCK_SIZE);
ram_destination = malloc(BLOCK_SIZE);
flash_block = mmap(0, BLOCK_SIZE, PROT_READ,MAP_PHYS|MAP_SHARED, NOFD,
flash_addr);
if (flash_block == MAP_FAILED) {
printf("Unable to map block at %lx
", flash_addr);
}
cycles_per_sec = SYSPAGE_ENTRY(qtime)->cycles_per_sec;
flashtime = CopyTest("flash", flash_block, ram_destination);
ramtime = CopyTest("RAM", ram_block, ram_destination);
printf("
Flash is %f times slower than RAM
", flashtime/ramtime);
return EXIT_SUCCESS;
}
Листинг 2. Код для измерения времени копирования из флеш-памяти.
Для получения достаточно точных результатов нужно запустить программу Листинга 2 либо с высоким приоритетом (используя команду on –p), либо тогда, когда в системе еще мало что работает.
Ключевым фактором, влияющим на время копирования из флеш-памяти, является интерфейсная шина к этой памяти. Как показано в табл. 2, преимущество быстрого ЦПУ может потеряться по сравнению с его более медленными конкурентами, если в системе используется архитектура с медленной шиной или с избыточными состояниями ожидания.
|
Архитектура |
Тактовая частота |
Измеренная скорость копирования из флеш- памяти ( на Кбайт данных) |
|
SH-4 |
200 Мгц |
59 мкс |
|
ARM9 |
200 Мгц |
93 мкс |
|
PowerPC |
400 Мгц |
514 мкс |
Таблица 2. Пример, показывающий время копирования из флеш-памяти.
Почему же не запускать выполнение программы прямо из флеш-памяти, минуя стадию копирования? Дело в том, что чтение из флеш памяти – операция медленная, и ее надо избегать. Заставляя ЦПУ непрерывно брать коды из флеш-памяти, вы, конечно, сэкономите некоторое время в начале, но крайне низкая производительность впоследствии сведет на "нет" все преимущества. Тем не менее, имеет смысл рассматривать и такую стратегию, но тогда кеш-память для инструкций должна превышать размер образа ОС.
Уменьшение размера фрагмента программы этапа Запуск
Программа для этапа Запуск имеет маленький размер (примерно 45 К), поэтому трудно получить для этой программы какие-либо значимые результаты по уменьшению размера. Если вы используете комплект разработчика QNX для быстрой активации устройств – Instant Device Activation Technology Development Kit (IDA TDK), – то ваши мини-драйверы будут скомпонованы в программу Запуск, и, следовательно, увеличат время загрузки. Поэтому убедитесь в том, что мини-драйверы имеют как можно меньший размер – не перегружайте их большим количеством неиспользуемого кода отладки или вызовами kprintf().
Удалите ненужный вывод отладочной информации
Вызовы меток-идентификаторов (callouts) на этапах работы программ НЗ и Запуск обрабатываются как вызовы на выдачу отладочной информации на печать, что происходит на ранних этапах загрузки системы (до загрузки драйвера последовательного канала). Обычно подпрограммы этих вызовов производят запись непосредственно в регистры первого UART. Однако до этапа 3 процесса начальной загрузки в системе не доступны никакие прерывания. Поэтому после заполнения буфера FIFO микросхемы UART подпрограмма не сможет записать в буфер FIFO ни одного символа, пока буфер не начнет очищаться. Для стандартного UART быстрая по замыслу процедура этапа Запуск может сильно замедлиться, если вы перегрузите процесс начального запуска выдачей слишком большого числа сообщений.
-
Закомментируйте ненужные строки с командами kprintf(). Просмотрите текст программы main(), касающийся этапов НЗ и Запуск, найдите там все ненужные фрагменты с вызовами kprintf() и закомментируйте их.
-
Сократите количество многократно используемых ключей –v. В сценарии компоновки найдите вызовы микроядра (procnto) и уменьшите количество использованных ключей -v. Например, если строка выглядит так:
PATH=:/proc/boot:/bin:/usr/bin
LD_LIBRARY_PATH=:/proc/boot:/lib:/usr/lib:/lib/dll procnto –vvvv то замените -vvvv на -v или просто удалите этот ключ.
-
Удалите вызовы функции display_msg. В сценарии компоновки удалите все вызовы функций display_msg, где происходят вызовы меток-идентификаторов (callouts) на этапе Запуска. Сюда входят все команды вызова display_msg, предшествующие такой последовательности:
waitfor /dev/ser1
reopen /dev/ser1
Эти операторы перенаправляют вывод для последовательного канала на вновь загружаемый драйвер (обычно строка выше оператора waitfor), который будет вызываться по прерыванию, и при этом не будет стадии ожидания.
-
Не используйте низкие скорости передачи последовательного канала. Для вывода на консоль не используйте скорости передачи меньше чем 115200 бод, если в этом нет абсолютной необходимости. В противном случае вы рискуете "застрять" в цикле работы процедуры printf() при исполнении ядра, когда буфер FIFO UART перейдет в состояние ожидания, пока не будут отправлены накопленные символы и не освободится место для приема новых. Есть шанс, что вы так не поступите по единственной причине: все это очень медленно. Однако в системах с малым числом каналов UART может возникнуть искушение совместно использовать канал для вывода на консоль и на устройство GPS, работающее на скорости 9600 бод. Если вы сделаете это, и у вас по-прежнему сохранен вывод отладочной информации в последовательный канал при работе ядра или на этапе Запуск, то вы серьезно "сбросите скорость" работы кода из-за фаз ожидания при использовании низкой скорости передачи.
Уменьшайте размер файловой системы на базе образа ОС (IFS)
Как уже говорилось ранее, на этапе Запуск происходит копирование файловой системы на базе образа ОС (IFS) из флеш-памяти в ОЗУ. Микроядро и приложения могут начать работу только после завершения этой операции копирования. Поэтому чем меньше будет размер IFS, тем раньше может быть запущена работа всех компонентов.
-
Удалите все неиспользуемые исполняемые процедуры. Удалите из IFS любые неиспользуемые в работе фрагменты исполняемых процедур, начиная с процедур большого размера. Прежде чем "подрезать все под ноль" и удалять процедуры, которые могут помочь в отладке целевой платформы, проведите измерения скорости копирования из флеш-памяти в ОЗУ (см. Листинг 2). Если получен результат 100 мкс/Кбайт, то копирование исполняемого блока размером 40 К займет 4 мс. Удаляйте из образа фрагменты исполняемого кода лишь в том случае, когда выигрыш во времени загрузки перевесит потери от удаления полезного инструмента.
Имейте в виду, что нет необходимости вручную "вычищать" исполняемый код от внедренных в него отладочных фрагментов. Процедура mkifs проделает это автоматически. Помните, что mkifs не работает по бинарному файлу – это нужно делать во время компоновки (работы со сборочным файлом проекта).
-
Используйте символические ссылки. Разделяемые библиотеки в системе POSIX, включая ОСРВ QNX Neutrino, обычно имеют в системе два представления: регулярное имя файла (с номером версии) и символическая ссылка (без номера версии). Например, libc.so.2 и libc.so. В целевой системе должны содержаться оба представления. Таким образом, код, для которого требуется конкретная версия разделяемой библиотеки, может быть скомпонован с этой версией, а код, где эти требования не предъявляются, компонуется с версией общего назначения. Для системы Windows, где не поддерживаются истинные символические ссылки, при инсталляции среды QNX Momentics вместо символических ссылок создаются дубликаты соответствующих файлов.
Если в вашей целевой системе используются представления разделяемых объектов, привязанные и не привязанные к версии, найдите время сделать привязку одной символической ссылки к другой. Это можно сделать либо в среде IDE, либо в сценарии компоновки. В противном случае вы можете получить в образе IFS результат компоновки с двумя различными копиями исполняемых кодов. Поскольку многие исполняемые библиотеки имеют большой размер (например, размер библиотеки libc.so варьируется от 600 К до 700 К), то выполнение указанной рекомендации может значительно сократить размер образа IFS.
-
Переместите выбранные файлы в EFS. Если какой-либо файл не нужен во время процесса раннего запуска системы, то переместите его во флеш-память внешней файловой системы (external file system, EFS). Образ IFS, имеющий маленький размер, включает в себя микроядро, библиотеку libc, драйвер UART, драйвер флеш-памяти и больше ничего. После загрузки драйвера флеш-памяти могут быть автоматически смонтированы разделы EFS, после чего начинается установка оставшихся драйверов или приложений из EFS.
Здесь конечно есть альтернативы. Образ IFS полностью загружается из флеш-памяти как один большой блок. Будучи загруженным в IFS, любой запускаемый через IFS исполняемый код будет выполнять загрузку из ОЗУ в ОЗУ. Для EFS файлы перегружаются из флеш-памяти в ОЗУ каждый раз, когда в них есть необходимость. Поэтому, если вам нужно во время начальной загрузки несколько раз загружать исполняемый блок, то может быть, лучше оставить его в IFS, потому что вы уже один раз "оплатили расходы" на его перегрузку из флеш-памяти.
-
Для удаления библиотек и функций, на которые нет ссылок, используйте системный оптимизатор. Во многих случаях можно значительно сжать размер образа IFS с помощью системного оптимизатора (известного под именем dietician) в системном компоновщике среды QNX Momentics. Системный оптимизатор производит поиск любых библиотек, на которые нет ссылок в исполняемом коде, и полностью их удаляет (см. рис. 2). Системный оптимизатор может также удалить функции из разделяемых объектов, если на эти функции в коде IFS совсем нет ссылок (см. рис. 3). В системном оптимизаторе будет создана специальная сокращенная версия разделяемых объектов, которые в среде IDE компонуются для использования в целевой системе. В среде IDE такие уменьшенные библиотеки размещаются в подпапке Reductions вашей основной папки с проектом для системного компоновщика.
Несколько пояснений:
-
Данный инструмент можно использовать только в среде QNX Momentics IDE; не существует эквивалентной команды, если вы захотите скомпоновать образ IFS, не используя среду IDE.
-
Сокращенные версии разделяемых объектов будут содержать только функции (файлы), требуемые для работы внутри образа IFS. Если вы вне IFS добавите бинарный код, где есть вызов удаленных оптимизатором функций, то этот код работать не будет.
-
Системный оптимизатор не сможет найти код, если используется процедура dlsym() для динамической загрузки адресов функций. Чтобы обойти это ограничение, необходимо: а) создать фиктивную библиотеку, где есть ссылки на необходимые функции, так, что они будут принудительно включены, или б) не запускать работу системного оптимизатора для разделяемых объектов, если этот объект будет динамически загружаться с помощью процедуры dlopen().
-
Каждый раз, когда запускается системный оптимизатор, будут генерироваться новые версии разделяемых объектов. Это может потребовать дополнительных усилий по управлению конфигурацией проекта, чтобы отслеживать лишние сокращенные копии библиотек.
-
Вы не будете использовать версии библиотек “QNX-blessed”.
Несмотря на эти особенности, системный оптимизатор является очень полезным и относительно легко используемым средством сокращения размера образа IFS. Отброшенный код непосредственно приводит к уменьшению времени загрузки. В табл. 3 приведен пример того, как выбранные действия (см. рис. 2 и 3) приводят к уменьшению размера типичного образа IFS. В этом образе содержится полный набор файлов, необходимых для работы пакета BSP, но нет никакого кода приложений. Конечно же, размер образа может меняться в зависимости от того, насколько полно в бинарном коде вашего образа IFS используются функции из разделяемых библиотек. Чем больше функций вызывается, тем меньше объектов можно будет удалить, тем меньше будет получаемая экономия.
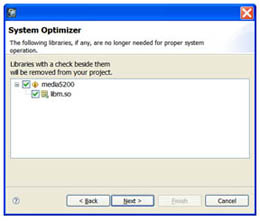 |
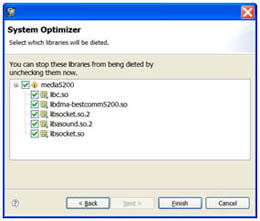 |
|
Рис 2. Использование системного оптимизатора для удаления неиспользуемых библиотек. |
Рис 3. Использование системного оптимизатора для удаления функций из библиотек. |
|
Библиотека |
Исходный размер |
Уменьшенный размер |
Количество удаленных байт |
% уменьшения |
|
libc.so |
716K |
499K |
217K |
30% |
|
libsocket.so |
173K |
144K |
29K |
17% |
|
libdma-bestcomm.so |
39K |
28K |
11K |
28% |
|
libm.so |
174K |
0 (удалена) |
174K |
100% |
|
Всего |
1102K |
671K |
431K |
39% |
Таблица 3. Пример уменьшения размеров библиотек, сделанного системным оптимизатором.
Стратегии сжатия
Можно выполнить сжатие либо всего образа IFS, либо сжимать отдельные файлы в EFS. (Если используется комплект QNX Instant Device Activation TDK, то вы не сможете выполнить сжатие образа IFS.) Кроме уменьшения места, занимаемого во флеш-памяти, сжатие может также сократить время начальной загрузки. В системах с очень большим временем доступа к флеш-памяти часто получается, что быстрее развернуть сжатые файлы из флеш-памяти, чем делать прямое копирование несжатых файлов большего размера. Если временные параметры работы вашей системной флеш-памяти относятся к категории медленных (по данным табл. 2), то попробуйте использовать сжатие. Инструкции развернутого сжатого кода могут запускаться прямо из командного кеша ЦПУ. Конечно, надо учитывать и то, что система делает во время загрузки. Нужно попробовать оба подхода и выбрать наилучший вариант.
Используемый по умолчанию сценарий компоновки
Файлы для компоновки, обычно поставляемые в составе QNX, содержат много компонентов, которые для минимальной конфигурации системы оказываются закомментированными. Снимите символ комментария с необходимых вам компонентов, но вначале определите, что вам действительно нужно:
-
slogger — системный регистратор, с помощью которого поступают сообщения об ошибках от компонентов QNX, это полезно на этапе разработки. Однако для вашей конечной законченной системы вряд ли потребуется доступ к выдаваемым ошибкам. Если это так, то в сценарии конечной компоновки вам не нужна функция slogger (или sloginfo для данной ситуации). Можно отключить также и функцию slogger, если вы используете свою подсистему протоколирования.
-
pipe — эта функция поддерживает конвейерный вывод в POSIX (например, ls | more). Конвейерный вывод можно использовать и программно без использования сценария. Во многих встраиваемых системах конвейерная обработка не используется, так что эту функцию можно удалить.
-
devc-pty и qconn — эти процедуры также необходимы на этапе разработки и отладки, в готовой системе их можно удалить.
Куда поставить команду Waitfor?
В сценарии компоновки многократно используются вызовы команды waitfor, чтобы обеспечить загрузку требуемого ресурса прежде любой из использующих его далее программ. Это грамотный подход, поскольку программа может дать сбой, если не будет найден необходимый ресурс. Однако в прилагаемом по умолчанию сценарии компоновки вызовы waitfor размещены в основном, исходя из соображений здравого смысла, чем с точки зрения обеспечения максимальной производительности. Рассмотрим это на примере Листинга 3.
.
.
.
# Starting PCI driver
pci-mgt5200
waitfor /dev/pci 4
# Starting Network driver
io-net -dmpc5200 verbose -ptcpip
waitfor /dev/io-net/en0 10
ifconfig en0 192.168.0.2
# Starting Flash driver...
devf-mgt5200 -s0xfe000000,32M
waitfor /fs0p1
/fs0p1/dumper &
# Starting USB driver...
io-usb -dohci-mgt5200 ioport=0xf0001000,irq=70
waitfor /dev/io-usb/io-usb 4
.
.
.
Листинг 3. Сценарий компоновки с исходным размещением вызовов команды waitfor.
В этом сценарии используется разумный подход: запускается драйвер, а потом ожидается его полная загрузка, прежде чем продолжится выполнение последующих шагов. Некоторые из драйверов требуют инициализации аппаратуры. Если драйверу действительно нужно ожидать готовности аппаратуры, то команда waitfor может предотвратить преждевременную загрузку следующей программы.
Алгоритм поведения команды waitfor очень прост: программа сканирует указанное устройство, и, если устройство не найдено, то дается выдержка в 100 мс, затем попытка повторяется. Команда завершается либо при нахождении устройства, либо по истечении заданного времени ожидания, в зависимости от того, какое событие произойдет раньше. В результате команда waitfor может вообще ничего не делать, кроме циклического опроса, задерживая работу всех последующих программ. Вы хотите 100%-ного использования ЦПУ на этапе начальной загрузки, а тут длительность загрузки увеличивается за счет лишних простоев. В идеале команда waitfor должна сделать единственную попытку доступа к устройству, которая должна оказаться успешной, после чего продолжается дальнейшая работа по сценарию. Упорядочение процесса логического группирования может минимизировать неоправданные "засыпания" путем использования загрузки других программ, обеспечивающих необходимые задержки.
Например, вам надо запустить драйвер IDE во время этапа начальной загрузки. Этот драйвер должен ждать окончания инициализации оборудования, операции, требующей времени около 100 мс. Что делает команда waitfor: она ждет полной инициализации оборудования, прежде чем идти дальше. Но зачем терять даром эти 100 мс? После запуска драйвера IDE запустите драйвер USB (или другую программу), которая эффективно использует это время. Если для драйвера USB нужно 100 мс для подготовки оборудования, вы уже получили дополнительное "бесплатное" время. Зато когда вам фактически потребуется среда IDE, результат тестирования командой waitfor мгновенно даст положительный результат. При этом вы сократили полное время загрузки.
Пример изменения сценария такого рода приведен в Листинге 4.
.
.
.
# Starting PCI driver
pci-mgt5200
# Starting Network driver
io-net -dmpc5200 verbose -ptcpip
# Starting Flash driver...
devf-mgt5200 -s0xfe000000,32M
# Starting USB driver...
io-usb -dohci-mgt5200 ioport=0xf0001000,irq=70
# Move these after other driver launches
# to make sure hardware has had enough delay
waitfor /fs0p1
/fs0p1/dumper &
waitfor /dev/io-net/en0 10
ifconfig en0 192.168.0.2
# Nothing utilizes these devices within this block,
# so these waitfors have been moved to the bottom.
# The intervening code has taken the place of any
# needed delays.
waitfor /dev/pci 4
waitfor /dev/io-usb/io-usb 4
.
.
.
Листинг 4. Последовательность сценария компоновки с измененным порядком размещения команды waitfor.
На рис. 4 и 5 показаны преимущества, получаемые в результате оптимизации размещения команды waitfor.
У этого метода есть один потенциальный недостаток: драйвер может не ожидать готовности оборудования, но, тем не менее, используя процессор выполнять реальное дело. В этом случае описанное выше изменение порядка команд приведет к тому, что все драйверы будут загружены сразу, в результате планировщик будет непрерывно переключаться между активными потоками. Это может быть менее эффективно, чем первый метод.
Для того, чтобы определить, улучшит ли описанная реорганизация производительность загрузки, можно использовать команду tracelogger для захвата во время загрузки данных от системного профайлера. Если полученный "мгновенный снимок" покажет наличие временных фрагментов, когда ЦПУ простаивает после загрузки драйвера, а также покажет, что в ядро делаются вызовы каждые 100 мс, то это означает, что именно драйвер должен быть объектом применения данного метода.
Размещение команды waitfor по умолчанию
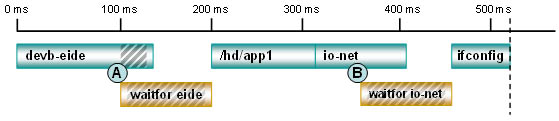
Рис. 4. Размещение команды waitfor по умолчанию.
В точке А драйвер EIDE начинает ожидание аппаратного прерывания. Поскольку заявленный ресурс недоступен на момент старта команды waitfor, то waitfor делает паузу в 100 мс. Тем временем оборудование заканчивает подготовку, и драйвер EIDE завершает свою работу. Но в связи с тем, что команда waitfor все еще заканчивает свой 100-мс интервал "сна", то возникает задержка в запуске следующего по очереди приложения app1 с жесткого диска. В точке В менеджер сети уходит в работу как сервер в фоновом режиме. В результате начинает выполняться следующая строка сценария с waitfor. Опять оказывается, что ресурс немедленно не доступен, команда уходит waitfor в цикл ожидания. Драйвер io-net завершает работу, не ожидая готовности оборудования, но из-за плохой организации команды waitfor система остается в простое и теряет время до того как будет запущена программа ifconfig.
Оптимизированное размещение команды waitfor
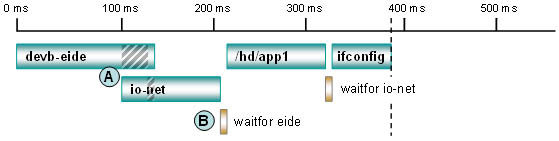
Рис. 5. Оптимизированное размещение команды waitfor.
В точке А по сценарию запускается драйвер io-net, при этом используется время простоя драйвера EIDE и не используется команда waitfor до тех пор, пока она действительно не будет необходима. В точке В система готова к запуску приложения app1, и команда waitfor немедленно завершается, потому что уже было достаточно времени, чтобы драйвер завершил работу. Приложение /hd/app1 запускается чуть-чуть позже, чем в сценарии по умолчанию, но в целом загрузка проходит гораздо быстрее.
Сравнение микроядра с монолитным ядром
Если вы продолжаете работать с архитектурой монолитного ядра, например, Linux или Windows CE, то вы, по-видимому, предпочитаете запускать все драйверы до того, как запускаются приложения. В случае ОС с микроядром, как ОСРВ QNX Neutrino, вам предоставляется больше гибкости, и можно реорганизовать процесс начальной загрузки, чтобы с пользой использовать время простоя. Под этим понимается запуск приложений до запуска драйверов, во всех случаях, когда это имеет смысл.
Например, система должна "прозвенеть" через секунду после включения питания. Для этого можно легко перестроить последовательность запуска, чтобы утилита "звонок" запускалась сразу же после загрузки аудио-драйвера. Можно также переместить момент загрузки аудио-драйвера перед всеми остальными драйверами. (Вероятно, самыми первыми все же запускаются драйверы флеш-памяти и последовательного канала.)
При таком подходе проигрывание звукового файла начнется еще в то время, когда продолжается загрузка системы. Другими словами, вы не помещаете запуск проигрывания мелодии в состав процедуры main(), где обычно прописывается запуск приложений. Проигрывание аудио-мелодии может быть маленькой одноразовой утилитой, которая завершается сразу по окончании мелодии. Такой подход дает возможность загружать оставшиеся драйверы и приложения, пока играет мелодия.
Модульное или монолитное построение приложения?
Если вы создаете систему, где имеется единственное главное приложение, то никакие предусмотренные приложением действия не будут выполняться до тех пор, пока в память не будет загружено все приложение целиком. Чем больше размер приложения, тем большие проблемы оно создает. Соответственно, часто имеет смысл составить вашу программную систему из нескольких логических модулей, которые запускаются как отдельные процессы. Эти процессы могут взаимодействовать между собой через любые механизмы межпроцессного взаимодействия (IPC). Использование отдельных процессов дает также большую гибкость с точки зрения порядка загрузки, при условии, что эти процессы не являются полностью зависимыми друг от друга. В качестве преимущества вы получаете дополнительный уровень защиты, благодаря изолированности процессов в памяти.
Время загрузки библиотек
Разделяемые библиотеки тоже требуют времени на загрузку. Когда приложение компонуется с разделяемым объектом, то загрузчик процесса сначала проверяет, загружен ли уже разделяемый объект. Если объект не загружен, то вначале должна произойти его загрузка из постоянной памяти (IFS, EFS или еще откуда-то). Процедура загрузки различных секций исполняемого кода из файла может потребовать некоторого времени. Даже если разделяемый объект уже находится в памяти, приложению может потребоваться время на выполнение адресной привязки. Динамический компоновщик должен просмотреть символические имена для присваивания им соответствующих адресов.
Для разделяемых объектов большого размера может оказаться, что в приложении лучше использовать статические ссылки с большими библиотеками. Поступая так, вы затрачиваете дополнительное время на этапе компоновки и компиляции, зато экономите время на этапе выполнения. Конечно, использование статических ссылок потребует большего размера флэш-памяти, если к этой библиотеке обращаются несколько приложений. Такой метод может также привести к несовместимости версий для разных приложений, если разделяемый объект изменяется, а вы не выполняете перекомпоновку ранее скомпилированного модуля. Но для некоторых систем выигрыш в производительности может перевесить этот недостаток.
Выбор языка
Есть вероятность, что вы не будете использовать язык Java на этапе ранней загрузки. Виртуальная машина Java (Java Virtual Machine, JVM) и ее библиотека классов должны быть загружены прежде любого из приложений. Операция загрузки дополнительных библиотек может добавить несколько секунд ко времени загрузки.
Аналогично, если вы используете язык C++, и у вас есть серьезные требования к скорости начальной загрузки, то вам нужно серьезно подумать о программной структуре системы. Аккуратное использование C++ не является большой проблемой. Однако приложения С++ имеют тенденцию получаться по размеру большими, чем приложения на языке С, особенно, если используются оболочки типа стандартной библиотеки шаблонов (Standard Template Library, STL). Эти оболочки могут многократно и в большом объеме использовать механизм динамического распределения памяти, а это отнимает дополнительное время. Кроме того, в языке С++ используются большие библиотеки разделяемых объектов, например, libcpp.so, которые вносят свой вклад в увеличение времени загрузки.
При использовании языка С++ постарайтесь, чтобы компоненты, для которых нужна быстрая загрузка, имели бы малый размер, с минимальным использованием шаблонов, структур приложений и глобальных конструкторов.
Подводя итоги
Разработчики и системные архитекторы могут использовать различные методики для удовлетворения требованиям начального этапа загрузки. Однако прежде чем использовать какую-либо из приведенных в данной статье стратегий, всегда помните о необходимости выработки стабильного способа измерения скорости загрузки системы. Тогда, если вы вносите какие-то изменения в систему, вы всегда сможете убедиться в наличии прогресса на пути к удовлетворению ваших требований.
О компании QNX Software Systems
QNX Software Systems является одной из дочерних компаний Harman International и ведущим глобальным поставщиком инновационных технологий для встраиваемых систем, включая связующее ПО, инструментальные средства разработки и операционные системы. ОСРВ QNX® Neutrino®, комплект разработчика QNX Momentics® и связующее ПО QNX Aviage®, основанные на модульной архитектуре, образуют самый надежный и масштабируемый программный комплекс для создания высокопроизводительных встраиваемых систем. Глобальные компании-лидеры, такие как Cisco, Daimler, General Electric, Lockheed Martin и Siemens, широко используют технологии QNX в сетевых маршрутизаторах, медицинской аппаратуре, телематических блоках автомобилей, системах безопасности и защиты, в промышленных роботах и других приложениях для ответственных и критически важных задач. Головной офис компании находится в г. Оттава (Канада), а дистрибьюторы продукции расположены в более чем 100 странах по всему миру.
|



